AI analytics across organizational boundaries – without sharing raw data. GDPR-compliant, data-sovereign, IDSA/GAIA-X compatible.
The “base” infrastructure of data spaces already includes key trust anchors with their IT and governance building blocks. Nevertheless: who is willing to share sensitive corporate data with partners? As a result, valuable data for important insights and new solutions often remain unused. Collaboration fails due to confidentiality, competition, and compliance.
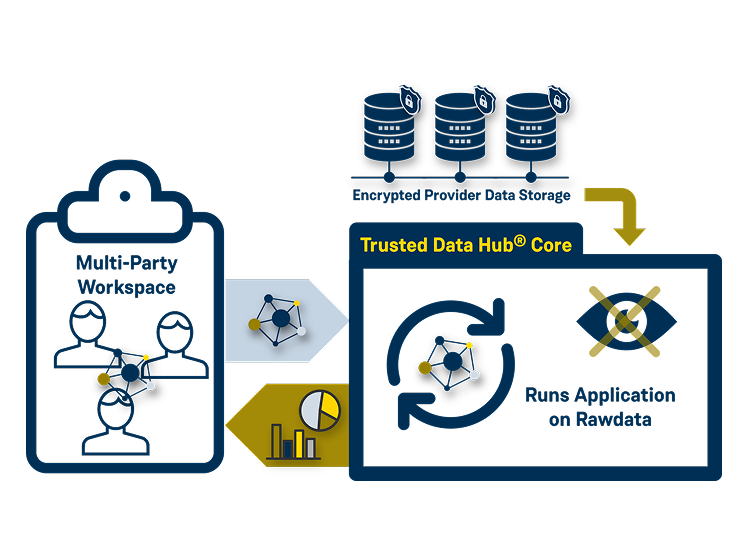
Our solution
The Trusted Data Hub (TDH) enables joint analytics/ML across multiple parties, without disclosing raw data. Data remains under the control of the owners; only results are shared. Sensitive data assets stay protected and compliance rules are observed. The TDH integrates seamlessly into data spaces.
Supply chain collaboration – merging data without exchanging raw data
Objective: Securely combine supplier, logistics and production data to enable ETA forecasts, inventory optimization, carbon footprint accounting and risk management. Raw data remains protected – only results and derived analyses are shared.
Data sources: Supplier master data & order call-offs, logistics & transport status (ETA, sensors), production & machine data, sustainability & emissions data
Example results: ETA forecasts for critical deliveries, optimized inventory levels and safety stock, carbon footprint accounting along the supply chain
Predictive maintenance – increasing availability through collaborative learning
Objective: Manufacturers and operators train joint ML models based on vibration, process and status data without revealing trade secrets. Objective: Avoid failures, increase availability.
Data sources: Vibration and sensor data from machines, process data from production and operation, condition data (temperature, pressure, running times), decentralized training approach (federated learning)
Example results: Prediction of failures and remaining useful life (RUL), recommendations for maintenance windows, optimization of spare parts and service deployments, increase in overall equipment effectiveness (OEE)
Collaborative condition monitoring – identifying patterns across the industry
Objective: Early detection of failures, drift or anomalies across fleets or industries without exchanging sensitive raw data. With strict access control and auditable usage rights.
Data sources: Condition and operating data from multiple plant operators, fleet and industry statistics, event data (failures, maintenance, anomalies), access control and audit mechanisms
Example results: Benchmarking of plant health across multiple operators, detection of drift patterns (e.g. wear trends), industry-wide early detection of critical failure patterns, audit-proof tracking of data usage.
Crisis/Resilience Analytics (PAIRS) – Cross-domain crisis data spaces
Objective: Use cross-domain data spaces (health, energy, logistics, etc.) for AI-supported crisis management – data-sovereign, secure, resilient. Only relevant results are shared.
Data sources: Health data (capacities, incidences), energy data (grid load, outages, consumption), logistics & transport events, social/news signals & open data
Example results: Scenarios for supply failures (electricity, health, logistics), courses of action for resource allocation (e.g. hospital beds, energy), interactive risk & resilience heat maps, AI-supported decision-making support for authorities & companies
Your next step: Request a prototype now
Experience your vision as a tangible prototype—without risk, without hidden costs. Request your customized rapid prototyping package today and secure a competitive edge.